
六、高可用的数据层架构
数据是最宝贵的资产。
数据存储高可用主要手段是冗余备份和失效转移机制。数据备份是保证数据有多副本,任意副本的失效都不会导致数据的永久丢失。从而实现数据完全的持久化。而失效转移机制是保证当一个数据副本不可访问时,可以快速切换访问数据的其他副本。保证数据可用。
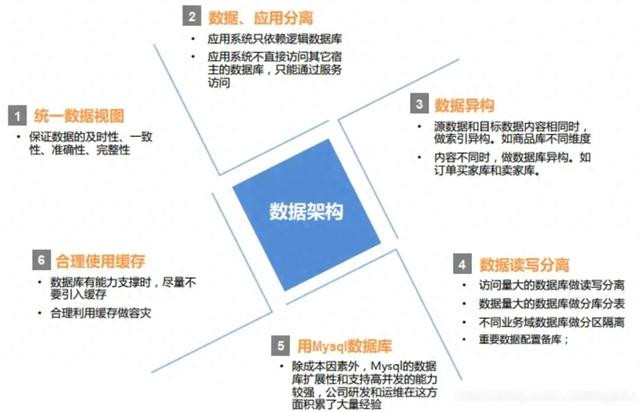
1、数据架构设计原则
2、数据一致性设计
1)分布式的 CAP 理论
在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),最多只能同时三个特性中的两个,三者不可兼得。
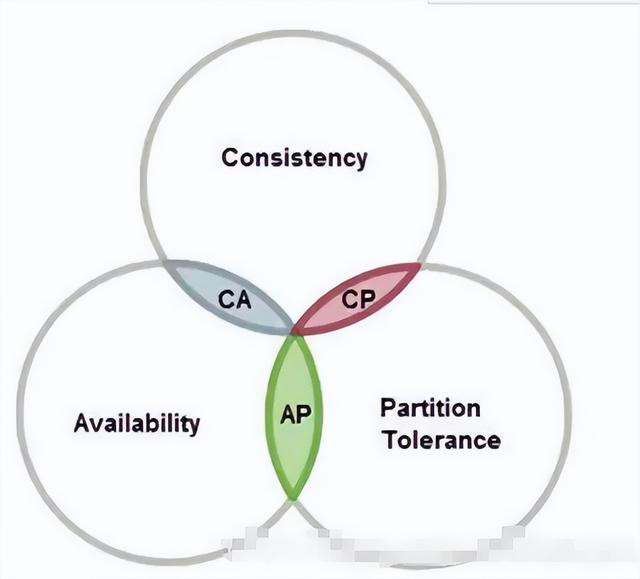
C 一致性(Consistency):说的是每一个更新成功后,分布式系统中的所有节点,都能读到最新的信息。即所有节点相当于访问同一份内容,这样的系统就被认为是强一致性的。
A 可用性(Availability):是每一个请求,都能得到响应。请求只需要在一定时间内返回即可,结果可以是成功或者失败,也不需要确保返回的是最新版本的信息。
P 分区容错性(Partition tolerance):是说在网络中断,消息丢失的情况下,系统照样能够工作。这里的网络分区是指由于某种原因,网络被分成若干个孤立的区域,而区域之间互不相通。
在非金融的互联网分布式应用里面,主机多,数据大,部署分散。所以节点故障,网络故障是常态。一般是为了保证服务可用性而舍弃一致性 C。即保证 AP。
2)分布式的 BASE 理论
BASE 理论,它是在 CAP 理论的基础之上的延伸。包括基本可用(Basically Available)、柔性状态(Soft State)、最终一致性(Eventual Consistency)。
基本可用:分布式系统出现故障的时候,允许损失一部分可用性。比如,阿里双十一大促的时候,对一些非核心链路的功能进行降级处理。
柔性可用:允许系统存在中间状态,这个中间状态又不会影响系统整体可用性。比如,数据库读写分离,写库同步到读库(主库同步到从库)会有一个延时,这样实际是一种柔性状态。柔性事务和刚性事务对立,刚性事务也叫强一致性,比如 ACID 理论。
最终一致性:例如数据库主从复制,经过数据同步延时之后,最终数据能达到一致。
柔性事务(遵循 BASE 理论)放弃了隔离性,减小了事务中锁的粒度,使得应用能够更好的利用数据库的并发性能,实现吞吐量的线性扩展。异步执行方式可以更好的适应分布式环境,在网络抖动、节点故障的情况下能够尽量保障服务的可用性 (Availability)。因此在高可用、高性能的应用场景,柔性事务是最佳的选择。
柔性事务对 ACID 的支持:
原子性:严格遵循。
一致性:事务完成后的一致性严格遵循,事务中的一致性可适当放宽。
隔离性:并行事务间不可影响;事务中间结果可见性允许安全放宽。
持久性:严格遵循。
在业内,关于柔性事务,最主要的有以下四种类型:
两阶段型:就是分布式事务两阶段提交,对应技术上的 XA、JTA/JTS。这是分布式环境下事务处理的典型模式。
补偿型:TCC 型事务(Try/Confirm/Cancel)可以归为补偿型。服务器A 发起事务,服务 B 参与事务,服务 A 的事务如果执行顺利,那么事务 A 就先行提交,如果事务 B 也执行顺利,则事务 B 也提交,整个事务就算完成。但是如果事务 B 执行失败,事务 B 本身回滚,这时事务 A 已经被提交,所以需要执行一个补偿操作,将已经提交的事务 A 执行的操作作反操作,恢复到未执行前事务 A 的状态。这个需要服务 A 可以幂等操作。
异步确保型:将一些同步阻塞的事务操作变为异步的操作,避免对数据库事务的争用。
最大努力通知(多次尝试):交易的消息通知与失败重试(例如商户交易结果通知重试、补单重试)
3、完善的数据备份和恢复机制
完善的数据备份和恢复机制能力,在发生数据丢失的时候,可以使用备份快速恢复。
七、服务运营
运营层面主要故障总结:
运营操作失误
缺乏应急机制。
缺乏故障处理机制。
缺乏故障演练,导致切流后引发更大故障。
具体措施:
1、故障预防
1)灰度发布
服务发布上线的时候,要有一个灰度的过程。先灰度 1-2 个服务实例,然后逐步放量观察。
A/B 测试就是一种灰度发布方式,指为产品已发布 A 版本,在发布 B 版本时,在同一时间维度,让一部分用户继续用 A 版本,一部分用户开始用 B 版本,如果用户对 B 版本没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到 B 版本上面来。灰度发布可以保证整体系统的稳定,在初始灰度发布时就可以发现及调整问题,以保证其影响度。
通过灰度发布降低发布影响面和提升用户体验,就算出问题,也只会影响部分用户,从而可以提前发现新版本中的 bug,然后在下一次发布前提前修复,避免影响更多用户;
灰度发布的主要分类:
金丝雀发布:在原有部署版本可用的情况下,同时部署新版本应用作为金丝雀。
滚动发布:一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。
蓝绿发布:蓝绿部署是不停老版本,部署新版本然后进行测试。确认 OK 后将流量切到新版本,然后老版本同时也升级到新版本。
2)容灾备份部署
备份:数据备份(热备,冷备(冗余),异地)
过载保护
同城多活-》异地多活
流量切换
重试,防雪崩(概率很小,成本很高)
3)故障演练
故障演练是应用高可用能力测评的核心, 通过例行化故障演练、找出系统风险点、优化业务系统、产出可行有效的故障处理预案。
2、完善的服务故障发现
1)监控告警机制
在高可用服务设计章节提到,核心服务可以监控:服务流量预警、端口存活、进程占用的资源、服务接口功能逻辑是否正常,应用 FGC 等情况,需要一个完善监控告警机制,并在告警后,通过一定的策略进行处理,以致服务可以快速恢复。例如,监控 FGC,如果在一分钟内存出现10次 FGC,自动重启服务。
网络流量监控 。
系统监控:服务器资源和网络相关监控(CPU、内存等) 。
日志监控:统一日志收集(各个服务)监控,跟踪(log2) 。
应用监控:端口存活、进程占用的资源,应用 FGC 等情况。
业务监控:服务接口功能逻辑是否正常。
立体监控:监控数据采集后,除了用作系统性能评估、集群规模伸缩性预测等, 最终目标是还可以根据实时监控数据进行风险预警,并对服务器进行失效转移,自动负载调整,最大化利用集群所有机器的资源。
2)全链路观测平台
构建服务全链路观测能力,并有效降低 MTTR 各项指标。
掌握数据分析方法,构建数据服务指标,有效评估业务整体服务质量,沉淀一般通用指标方案,能成功复用到其他项目。
八、高质量的服务管理
服务规范管理:CMDB 对项目、服务、服务器进行统一管理。
代码质量管理:通过 ci 工具流程快速检测代码规范和安全隐患。
自动化发布:发布不影响用户,完善发布流程,自动化发布,可以及时回滚 。
自动化测试:上线完成后进行全面自动化测试。
性能压测:通过对服务压测,了解服务可以承载并发能力,以致可以让运维通过预警进行服务器扩容 。
代码控制:测试环境使用测试分支,beta 环境发布 tag,线上使用该 tag 发布。
发布流程:规范上线发布流程。
灰度发布:灰度发布服务 。
应急处理机制 。
故障处理规范。
形成闭环管理:有迹可循,来源可溯、去向可查等完整的生命周期管理。
九、能力和职责
海恩法则提到:再好的技术、再完美的规章 , 在实际操作层面也无法取代人自身的素质和责任心 。
因此要做到高可用的架构设计,职责也要清晰明确,要不然出现问题,相互推诿,问题解决进度很慢,会直接影响业务服务可用性。
1、职责清晰明确
1)架构师职责:
高可用架构设计:包括业务流程,模块划分组合,框架设计,流程纰漏,最后架构设计,技术实现步骤。系统性的思考,权衡利弊,综合各种因素,设计出具有前瞻性的架构。
和运维协调沟通,提出高效的服务治理解决方案,把控服务质量管理。
协调沟通:开发之间沟通,产品之间沟通,市场沟通,运维沟通、沟通后产出图形化文档及设计。
规范和统筹:保证系统秩序,统一,规范,稳定,高效运行。
2)运维/SRE 职责:
熟悉系统技术架构,和架构师制定各种规范化要求。
和架构师共同协调沟通,对系统架构提出可靠性,伸缩,扩展,数据库切分,缓存应用等解决方案。
提供监控系统,自动化发布系统,代码管理,文档平台,自动运维平台等基础设施
制定运维规范。
建立运维安全体系。
建立容灾备份体系。
3)研发职责:
参与架构师的架构师设计,并根据设计实现具体细节。
针对开发功能进行自测,压测。
开发代码,使用工具或组件符合架构师制定规范。包括代码规范、文档规范。
代码部署符合运维部署规范要求。
2、作为架构师/SRE 具备能力
人的能力素质是解决问题的根本
作为架构师,需要能力:
"具备对操作系统、容器技术、网络,大型分布式微服务架构深入理解和实践经验。能理解业务的可靠性需求,转化为技术指标,运用云原生、混沌工程、全链路压测等技术手段,建立业务的可观测,提升业务的 MTBF(平均故障间隔时间 Mean Time Between Failure)、降低 MTTR(平均修复时间 Mean time to repair),通过系统与数据能力不断帮助业务取得成功"。
自动化体系建设能力:
能对日常发布、变更工作、容量规划进行主动的自动化体系建设,并能沉淀指导方法,有效指导多业务建设。
掌握故障预防和发现技巧:
掌握通过构建和实施全链路压测和混沌工程等故障预防手段提升 MTBF。
掌握通过构建和实施系统异常检测和监控告警机制等故障发现手段降低 MTTI。
构建观测平台能力:
具备构建服务全链路观测能力,并有效降低 MTTR 各项指标。
精通数据分析方法,构建数据服务指标,有效评估业务整体服务质量,沉淀一般通用指标方案,能成功复用到其他项目。
技术深度能力:性能分析,基础扎实,深入底层:
能多维度的分析业务的性能瓶颈,通过架构调整,内核、软件参数等手段调优,沉淀一般通用性调优方案。
技术广度能力:
理解云原生相关技术与生态,能指导业务架构、技术架构调整落地为云原生应用。
作者丨黄规速